Computer Operating System 导论 cs -> hardware(io cpu…) software(application) data
interface(接口) hard - hard example: USB
Virtual Machine 操作系统向用户提供一个容易理解和使用的计算机(虚拟的),用户对这个计算机操作将被操作系统转换成对计算机硬件的操作
计算机系统组成 CPU RAM DISK IOdevice …..
中断 当所有事情发生时,CPU收到一个中断信号
存储系统 cpu负责将指令从内存读入,所以程序必须在内存中才能运行
I/O结构
系统体系结构 单处理器系统
多处理系统 两个或多个CPU
集群系统 ->cloud computing 云计算 若干节点,多台计算机通过网络连接在一起,节点之间是松耦合关系
操作系统结构 单用户单道模式 多道程序设计 让CPU总有一个执行任务
分时系统(多任务系统) 多个用户共享一天计算机
提供服务
process Concept definition process in memory
concurrency
进程是一个程序的一次执行过程
PROCESS STATE Running:此时进程的代码在cpu上运行
process scheduling 进程切换 切换时机:
切换过程:
中断技术 当发生某个异常事件,中止cpu上现行程序的运行
外中断 来自cpu外部
内中断 硬件,程序异常,系统调用
中断处理过程 context:save the context of the excuting process
特权指令和非特权指令 privileged instructions: only in kernel mode process switch
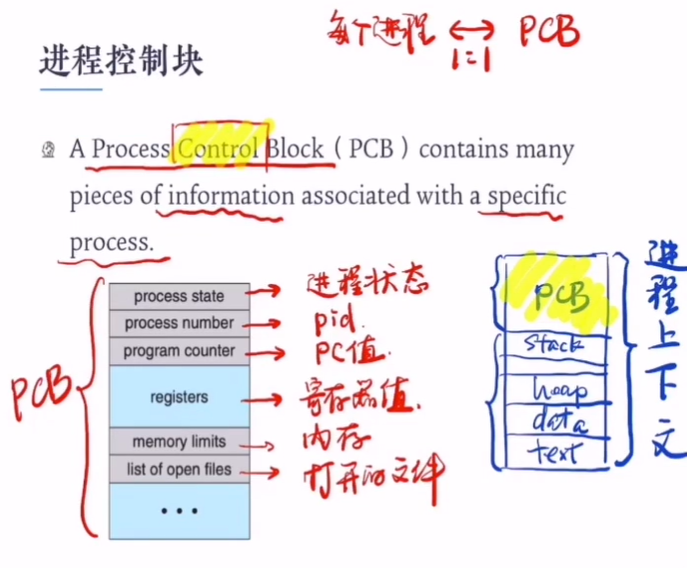
进程控制块
进程队列
进程调度
实验(创建子进程) getpid:返回当前进程的id
THREAD motivation 实现并行,把所有执行流封装到一个进程里
merit 响应性
DEFINITION Multithreading Model 用户线程 ULT在user mode下运行
内核线程 KLT在kernel mode下运行,由操作系统支持和管理
M:1模型
1:1模型 优:并发加并行
M:M模型 优:开销减小
多核编程
多线程实验 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <sys/types.h> #include <unistd.h> #include <stdio.h> #include <pthread.h> int value = 100;//共享数据部分属于进程 void* hello(void* arg) { for(int i = 0;i<3;i++) { printf("hello(%d)",value); sleep(1); } } void* world(void* arg) { for(int i = 0;i<3;i++) { printf("world(%d)",value); sleep(3); } } int main() { thread_t tid1,tid2; //线程创建函数 //1.第一个参数传线程id地址 //2.第二个参数传线程分配地址 //3.第三个参数传线程函数地址 //4.第四个参数传线程参数地址 pthread_create(&tid1,NULL,hello,NULL); pthread_create(&tid2,NULL,hello,NULL); //等待指定线程结束 pthread_join(tid1,NULL); pthread_join(tid2,NULL); printf("in main thread(%d)",value); }
所有线程共享数据段
等待线程结束的原因(thread_join):
实验中Linux命令:.c -o
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <sys/types.h> #include <unistd.h> #include <stdio.h> #include <pthread.h> #include <time.h> #include <stdlib.h> void * Caculate (void * arg) { unsigned seed = time(NULL ); int circle_point = 0 ; int square_point = 0 ; int value = *((int *)arg); for (int i = 0 ;i<value*value;i++) { double rand_x = (double )rand_r(&seed)/RAND_MAX; double rand_y = (double )rand_r(&seed)/RAND_MAX; if (rand_x*rand_x+rand_y*rand_y<=1 ) { circle_point++; } square_point++; } double PI = (4.0 *circle_point)/square_point; printf ("PI=%lf in %d times \n" ,PI,value*value); } int main () { int args[10 ]; clock_t delta; clock_t start = clock(); pthread_t calculate_pi_thread[10 ]; for (int i = 0 ;i<10 ;i++) { args[i] = 100 +i; pthread_create(calculate_pi_thread+i,NULL ,Caculate,args+i); } for (int i = 0 ;i<10 ;i++) { pthread_join(calculate_pi_thread[i],NULL ); } delta = clock()-start; printf ("total time is %lf\n" ,(double )delta/CLOCKS_PER_SEC); return 0 ; }
LECTURE 6 CPU SCHEDULING CPU调度程序 基于单处理器 长进程:占用cpu时间长
调度性能指标 ti = tf - ts;(进程提交给系统的时刻是ts,完成时刻是tf)
调度算法 FCFS(队列) FCFS
时间片轮转(TIME SHARING)
对长作业切换开销太大
最短作业优先(SJF) 下一次调度选择所需要的CPU时间最短的那个进程
优先级调度 调度策略:下次调度总是选择优先级最高的进程
优先级定义 在Linux中,线程调度优先级由一个整数值表示,范围从0到最高优先级(通常是99)。较高的优先级值表示线程具有更高的优先级。
静态优先级:优先级保持不变,但会出现不公平现象
调度
Linux 线程调度 1 2 pthread_attr_t attr //初始化线程属性为默认
1.Scope: PTHREAD_SCOPE_SYSTEM 系统 scs Linux 一对一模型
2.调度策略,调度优先级 Scheduling policy :
SCHED_OTHER: time -sharing NICE:友好值[-20,19] PR = 20+NICE[0,39] PR值越高,优先级越低
REAL TIME :PR = -1 - proirity_value
PR: rt —> PR = -100
‘chrt - p pid’->观察进程调度策略以及他的priority_value
调度策略的过程
LECTURE 7 进程同步 并发 在内存中存在若干进程或线程,由操作系统的调度程序采用适当策略将他们调度到CPU上运行,同时维护他们的状态队列
并发是交替执行
并发进程关系:
异步 1.random
可能是图中情况,也可能是先执行完t1再执行t2
同步 维护数据的一致性 数据(协作或交互的进程)
Mutex lock (互斥锁)解决竞争问题
互斥锁 进程进出临界区协议 进入临界区前在entry section要请求许可
管理准则:
1.section中有位置就必须进去一个
测试:y->获得锁 n-> waiting
上锁和测试不能被打断
原子操作 test_and_set()
busy waiting(自旋锁) 占用CPU执行空循环进行等待
1 2 3 4 5 6 //锁初始化 pthread_mutex_t lock = PTHREAD_MUTEX_INTIALIZER //获取锁 pthread_mutex _lock(&lock) //释放锁 pthread_mutex_unlock(&lock)
SIGNAL (信号量) PV操作
信号量的实现 1 2 3 4 5 6 7 8 9 10 11 P(s) { while(s<=0) do noing; s--; } V(s) { s++; }
s<=0 P(s) :busy waiting V(s) :s++
信号量的使用 BINARY SEMAPHORE
1 2 3 4 5 6 7 8 semaphore mutex = 1; process p { P(mutex); critical section V(mutex) }
1 2 3 4 5 6 7 8 semaphore road = 2; process Car { p(road); pass the fork in the road V(road); }
Lab
同步问题 找到并发进程交互点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Semaphore empty = 1 ; Semaphore full = 0 ; Producer { P(empty); put V (full) ; } Consumer { P(full); get V (empty) ; }
有界缓冲区
1 2 3 4 P(mutex); B[i] = product in = (in+1)%k; V(mutex);
1 2 3 P(mutex); product = B[out]; out = (out+1)%k
同步问题案例 读者写者问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 semaphore rw = 1,mutex=1; int reader = 0; Reader { p(mutex) if(reader==0) { reader++; p(rw); } v(mutex) read; p(mutex) reader--; if(reader==0) { v(rw); } v(mutex) } Writer { p(rw); writ e; v(rw); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #define Max 3 semphore b = 1,c = 0,mutex = 1; int waiting = 0; Barber { p(c); p(mutex); waiting--; v(mutex); cut hair v(b); } Customer { p(mutex); if(waiting<Max) { waiting++; v(mutex); p(b); v(c); } else { leaving } cut hair }
DEAD LOCK 在多并发进程下,一些进程会去竞争有限的资源,当资源不可用,进程会进入等待状态,在有些时候,等待状态无法被改变(他等待的资源被另外一个进程占有并等待)。
产生死锁必要条件:
解决方案 1.死锁的防止(Prevention) 破坏四个必要条件
2.死锁避免(Avoidance) 在并发进程中做出妥善安排避免死锁发生
SAFE STATE
Banker’s algorithm
3.死锁的检测和恢复
进程内存空间 逻辑地址和物理地址 16进制下,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 sample.o: file format elf64-x86-64 Disassembly of section .text: 0000000000000000 <sum>: 0: f3 0f 1e fa endbr64 4: 55 push %rbp 5: 48 89 e5 mov %rsp,%rbp 8: 89 7d fc mov %edi,-0x4(%rbp) b: 89 75 f8 mov %esi,-0x8(%rbp) e: 8b 55 fc mov -0x4(%rbp),%edx 11: 8b 45 f8 mov -0x8(%rbp),%eax 14: 01 d0 add %edx,%eax 16: 5d pop %rbp 17: c3 ret //逻辑地址:0,4,5..... 0000000000000018 <main>: 18: f3 0f 1e fa endbr64 1c: 55 push %rbp 1d: 48 89 e5 mov %rsp,%rbp 20: be 05 00 00 00 mov $0x5,%esi//参数传入调用函数 25: bf 04 00 00 00 mov $0x4,%edi//参数传入调用函数 2a: e8 00 00 00 00 call 2f <main+0x17>//调用函数 2f: 89 c6 mov %eax,%esi 31: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 38 <main+0x20> 38: 48 89 c7 mov %rax,%rdi 3b: b8 00 00 00 00 mov $0x0,%eax 40: e8 00 00 00 00 call 45 <main+0x2d> 45: b8 00 00 00 00 mov $0x0,%eax 4a: 5d pop %rbp 4b: c3 ret
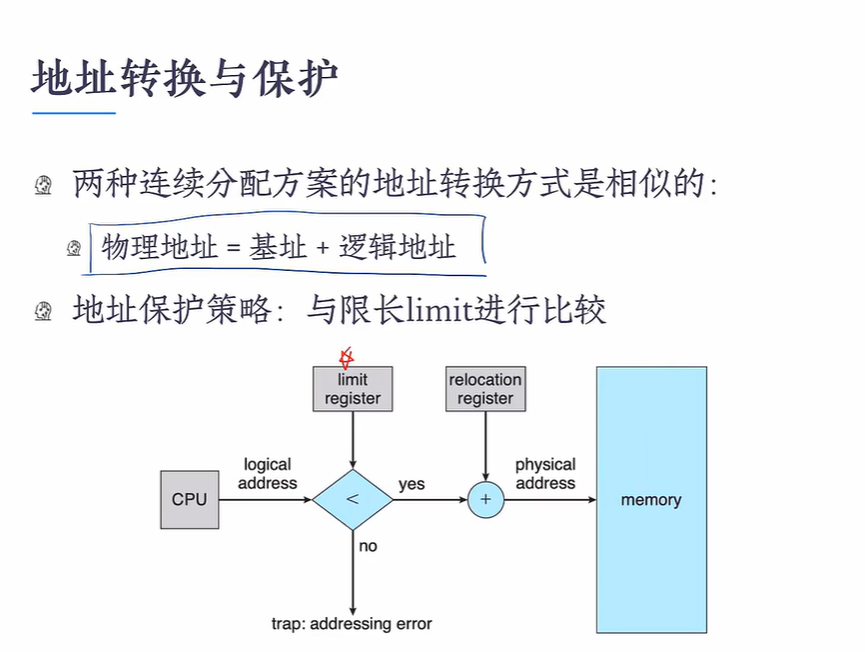
物理地址=基址+逻辑地址
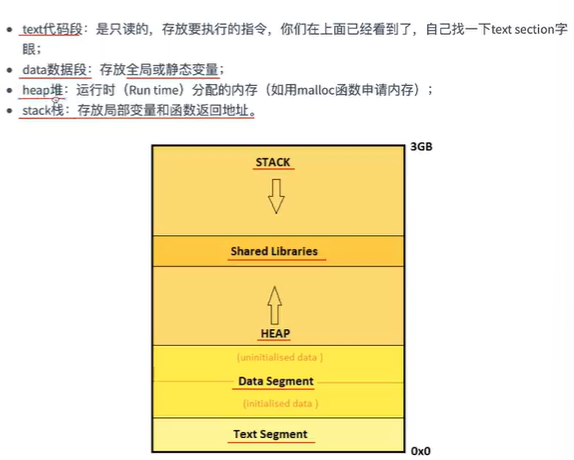
进程的内存映像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include<stdlib.h> #include<unistd.h> #include<stdio.h> int global_ar = 5; int main() { static int static_var = 6; int local_var=7; int *p= (int*)malloc(100); //use %lx to show a 64bits address printf("the global_var address is %lx\n",&global_var); printf("the static_var address is %lx\n",&static_var); printf("the local_var address is %lx\n",&local_var); printf("the address which the p points to is%lx\n",&p); free(p); sleep(1000); return 0; }
1 2 3 4 5 6 7 $gcc sample2.c -o sample2 $./sample2 #输出结果 the global_var address is 561b0368e010 the static_var address is 561b0368e014 the local_var address is 7ffe6aa505ec the address which the p points to is7ffe6aa505f0
1 2 3 4 ps -el 把sample2的pid记录下来 356275 pts/3 00:00:00 sample2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $cat /proc/356275/maps ## 输出结果如下 561b0368a000-561b0368b000 r--p 00000000 08:03 1051278 /home/null/Documents/expeiment/sample2 561b0368b000-561b0368c000 r-xp 00001000 08:03 1051278 ##代码段 /home/null/Documents/expeiment/sample2 561b0368c000-561b0368d000 r--p 00002000 08:03 1051278 /home/null/Documents/expeiment/sample2 561b0368d000-561b0368e000 r--p 00002000 08:03 1051278 /home/null/Documents/expeiment/sample2 561b0368e000-561b0368f000 rw-p 00003000 08:03 1051278 ## 数据段 /home/null/Documents/expeiment/sample2 561b04a41000-561b04a62000 rw-p 00000000 00:00 0 [heap] 7f1499a00000-7f1499a28000 r--p 00000000 08:03 919877 /usr/lib/x86_64-linux-gnu/libc.so.6 7f1499a28000-7f1499bbd000 r-xp 00028000 08:03 919877 /usr/lib/x86_64-linux-gnu/libc.so.6 7f1499bbd000-7f1499c15000 r--p 001bd000 08:03 919877 /usr/lib/x86_64-linux-gnu/libc.so.6 7f1499c15000-7f1499c19000 r--p 00214000 08:03 919877 /usr/lib/x86_64-linux-gnu/libc.so.6 7f1499c19000-7f1499c1b000 rw-p 00218000 08:03 919877 /usr/lib/x86_64-linux-gnu/libc.so.6 7f1499c1b000-7f1499c28000 rw-p 00000000 00:00 0 7f1499c7d000-7f1499c80000 rw-p 00000000 00:00 0 7f1499c8e000-7f1499c90000 rw-p 00000000 00:00 0 7f1499c90000-7f1499c92000 r--p 00000000 08:03 919871 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 7f1499c92000-7f1499cbc000 r-xp 00002000 08:03 919871 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 7f1499cbc000-7f1499cc7000 r--p 0002c000 08:03 919871 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 7f1499cc8000-7f1499cca000 r--p 00037000 08:03 919871 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 7f1499cca000-7f1499ccc000 rw-p 00039000 08:03 919871 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 7ffe6aa32000-7ffe6aa53000 rw-p 00000000 00:00 0 [stack] 7ffe6aba4000-7ffe6aba8000 r--p 00000000 00:00 0 [vvar] 7ffe6aba8000-7ffe6abaa000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
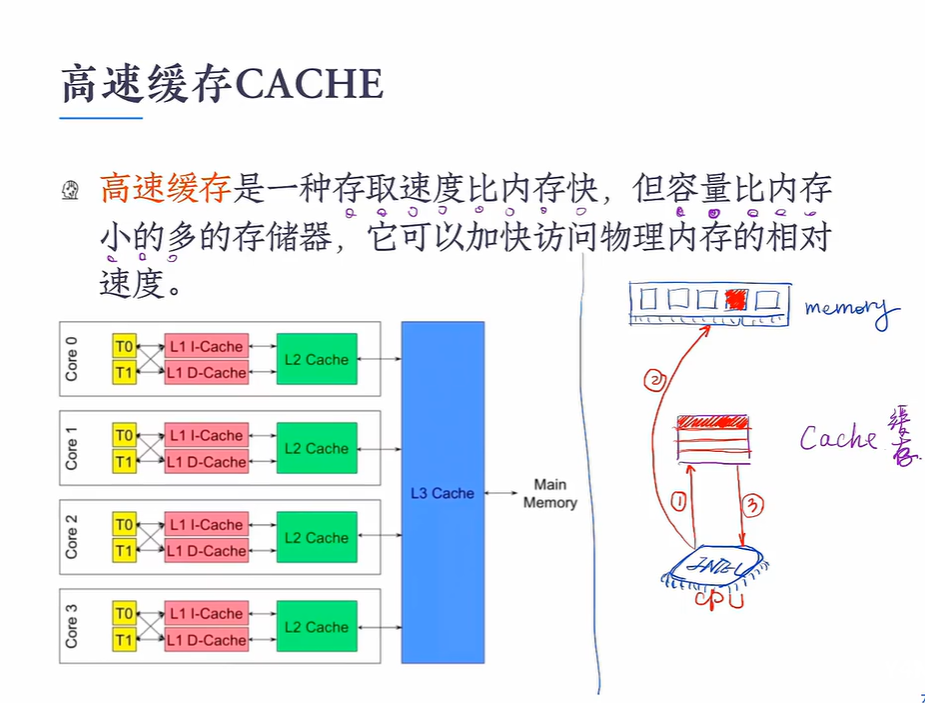
内存管理 目标 高速缓存
保护os: 防止用户进程去读写os的内存空间
保护用户进程:用户进程之间不能随意存取对方内存空间
操作正确:地址转换。分配回收
逻辑地址和物理地址 地址转换时机
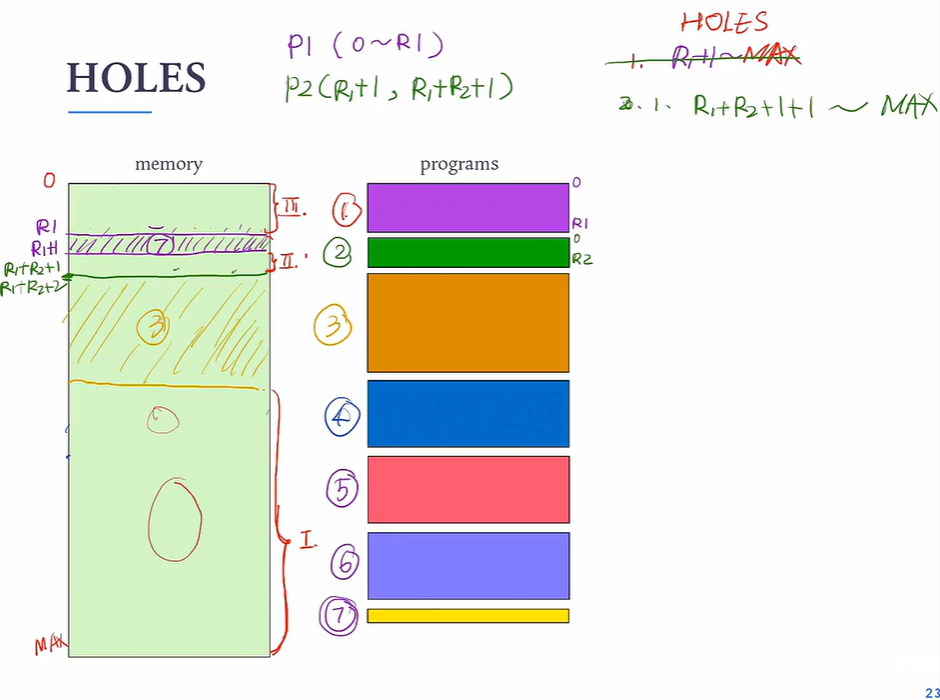
CONTIGUOUS MEMORY ALLOCATION FIXED_SIZED PARTITION 将内存划分成不同一些固定容量的分区,每个分区都可能包含一个进程
VARIABLE_PARTITION 可变分区
地址转换与保护:
碎片问题:
分段和分页 动机 针对碎片的解决方案
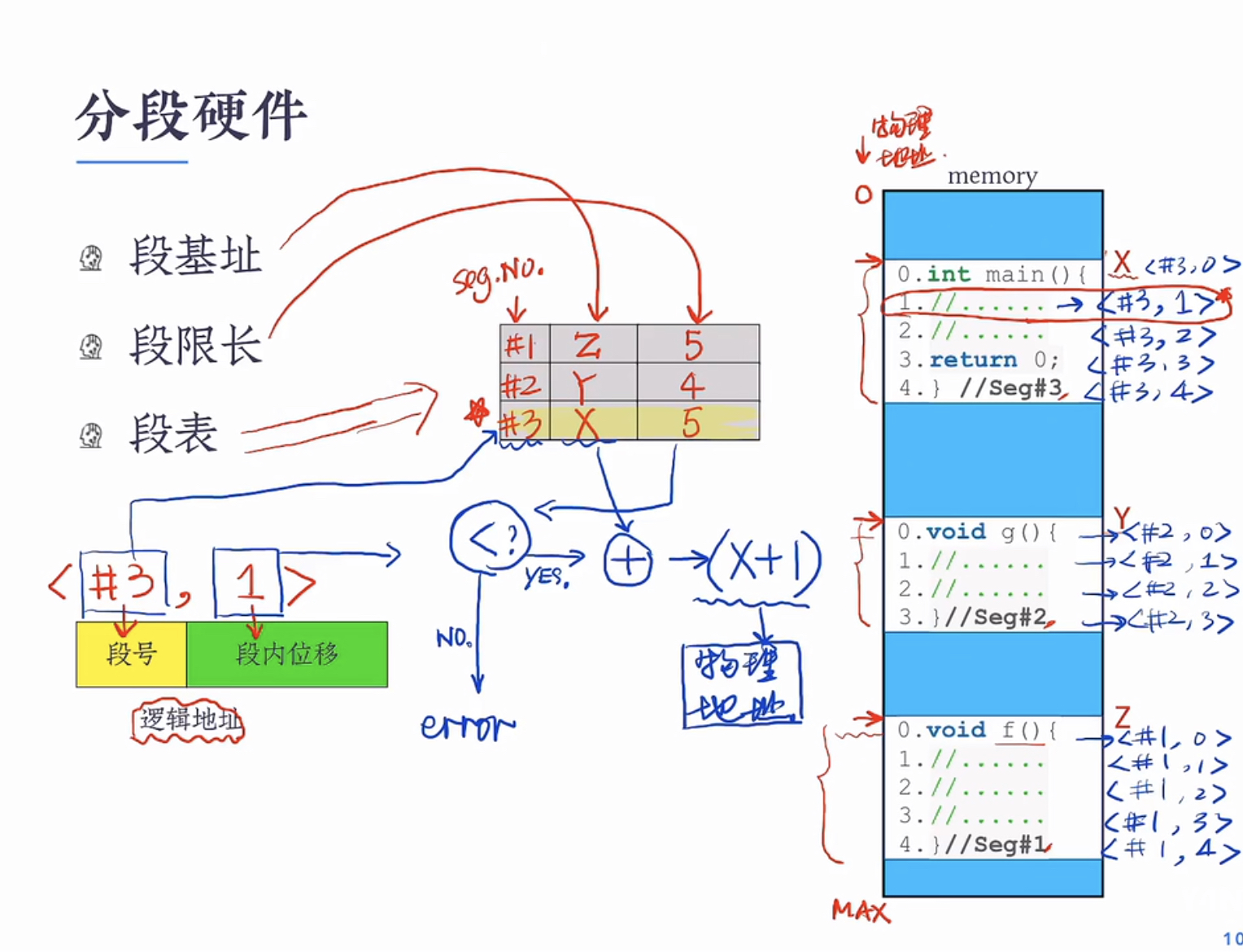
分段
分段硬件
16为位段式地址转换实例: pc寄存器存放的值是cpu下一条要执行的指令的地址
假设逻辑地址段号占2bits , 段内位移占14bits pc寄存器的值为0x240
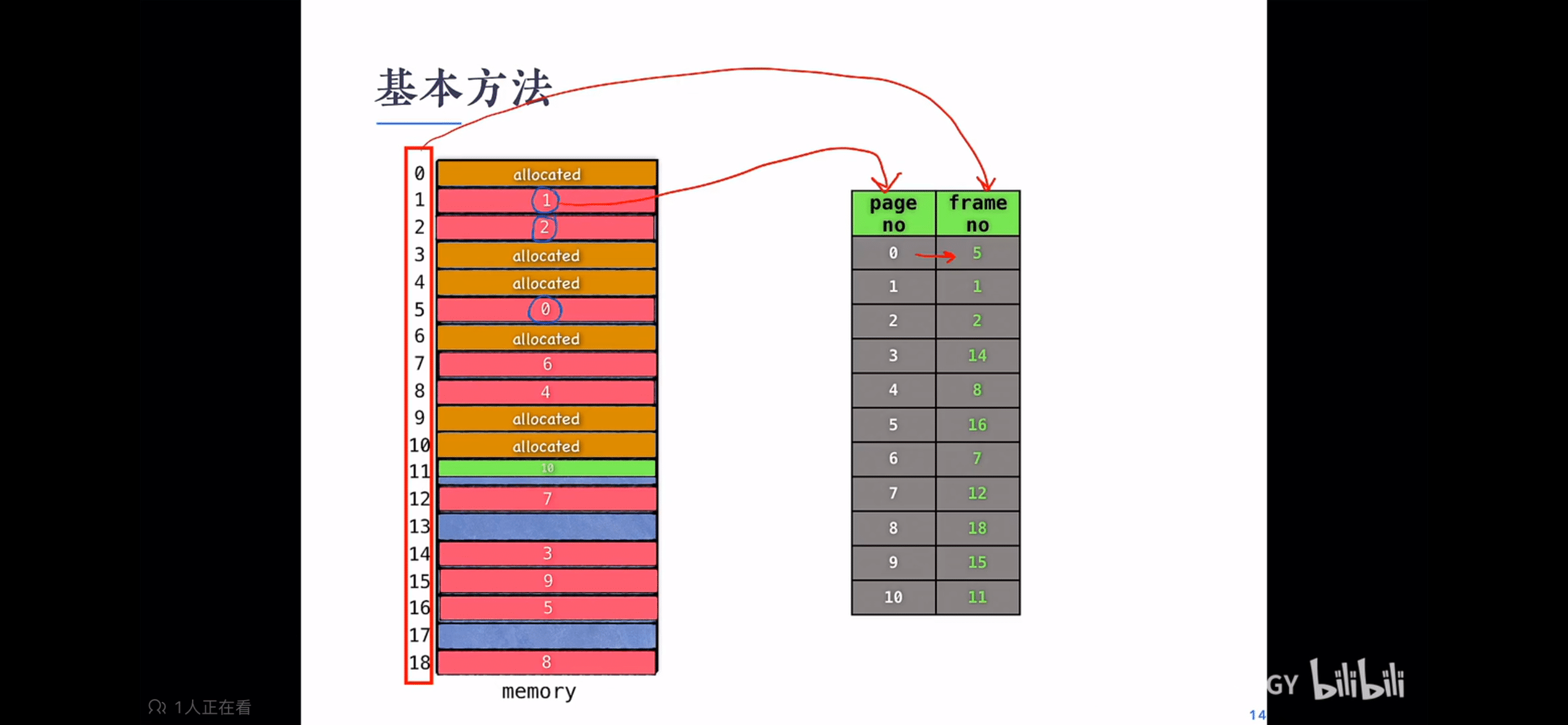
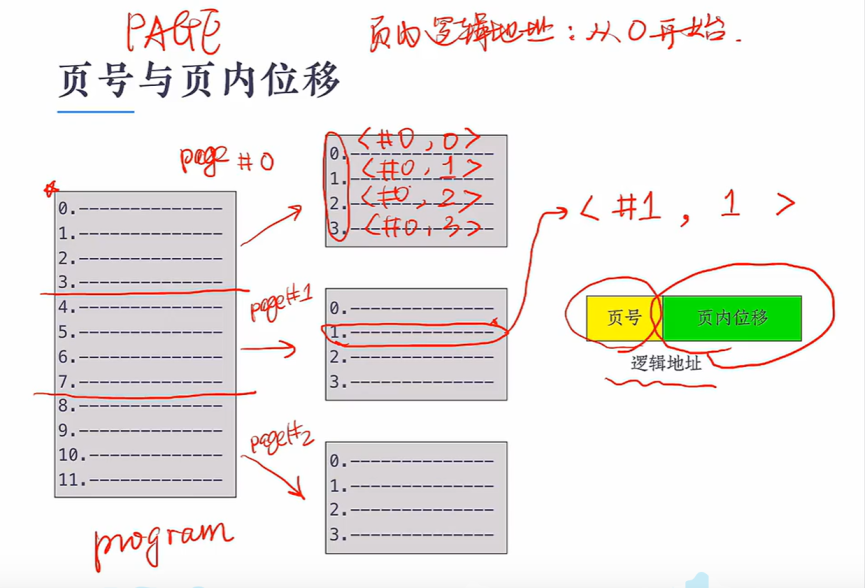
分页 frame:页框
页号和页内位移
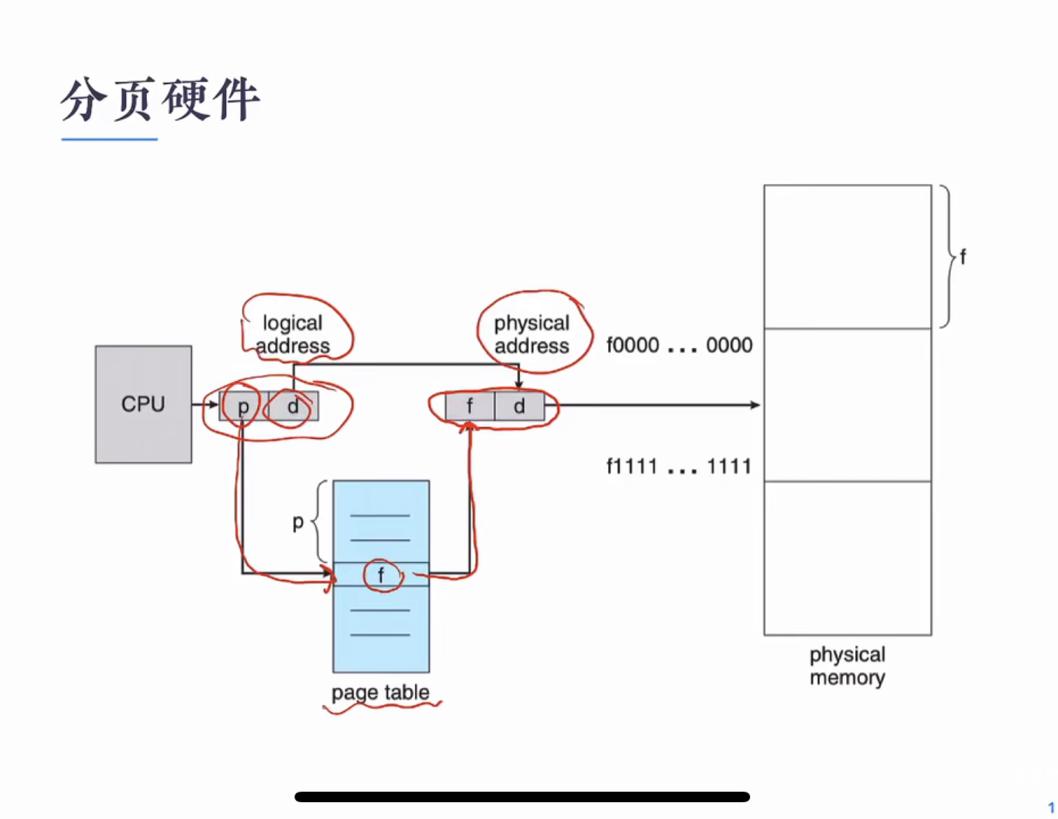
分页硬件
分页计算物理地址
页表 页面大小
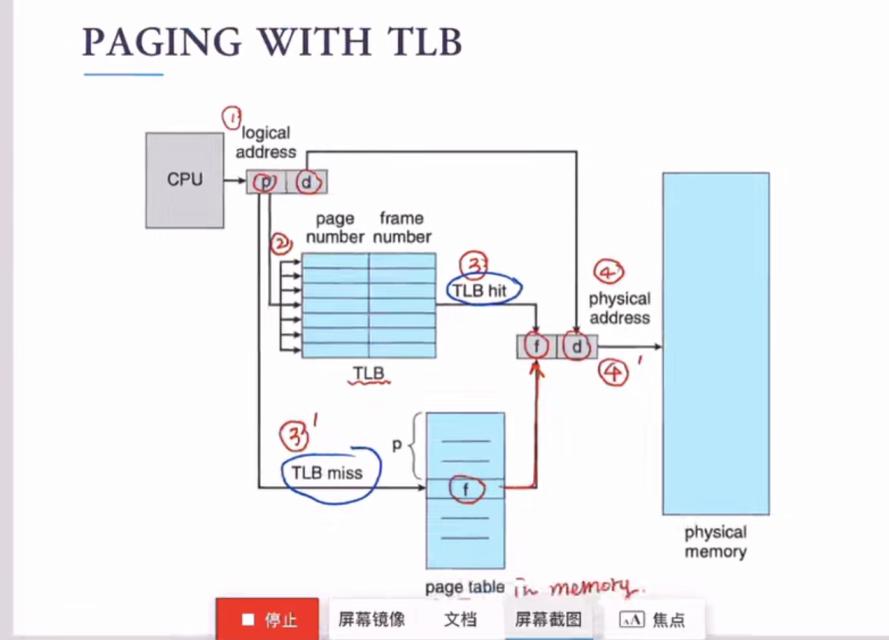
快表 TLB(Translation Look-aside Buffer)
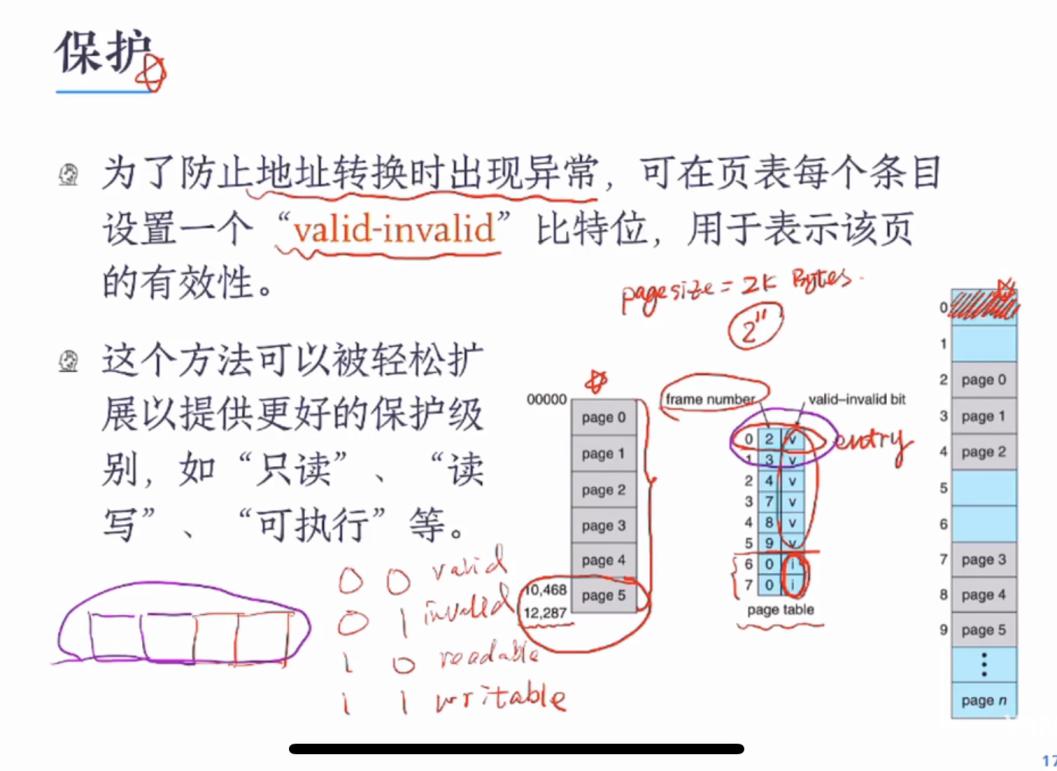
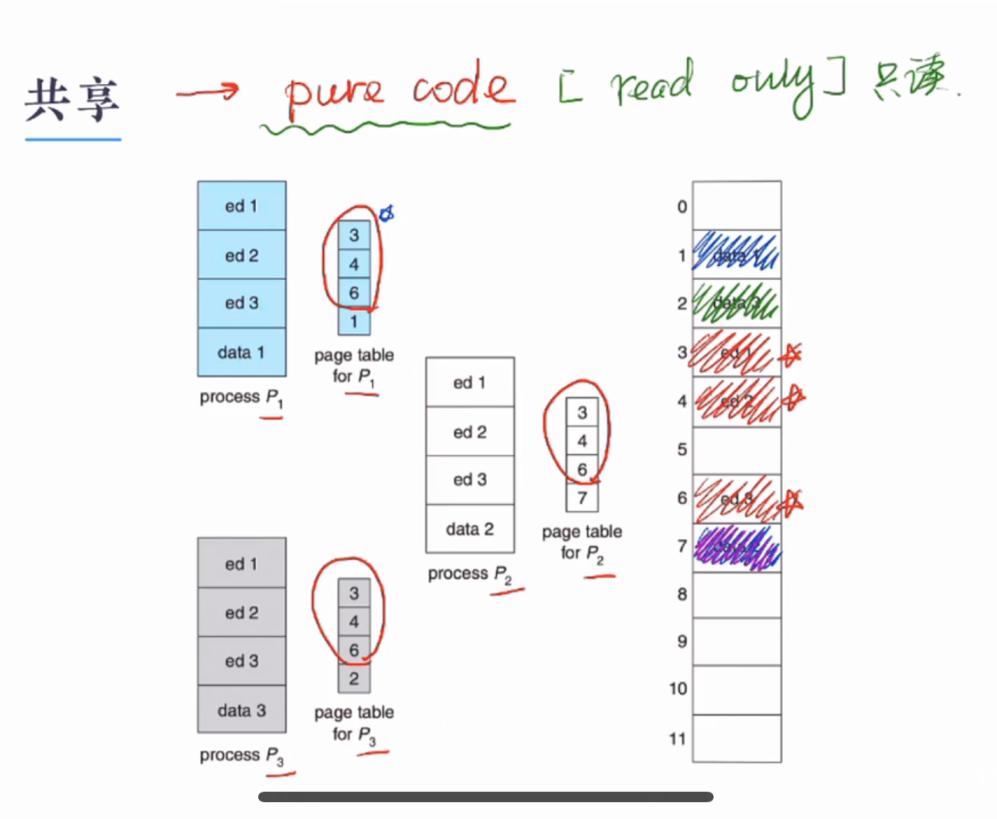
页的保护和共享
多级页表